Task-ID Conditioning as a Baseline for Multi-Task and Continual Learning
This article investigates whether a single, relatively small neural network can learn several different tasks without catastrophic forgetting. The study is framed as a mini-lab for multi-task and continual learning. The baseline is deliberately simple: concatenate a task identifier with the numeric input and train one multilayer perceptron (MLP) end-to-end. Task-ID conditioning therefore serves as a transparent baseline against which more advanced continual learning methods, such as Elastic Weight Consolidation (EWC) and replay strategies, can be compared.
The full experiment can be reproduced either in Colab or locally using the code here: Kaggle Notebook.
Introduction
Neural networks are most often trained to perform a single, well-defined task. At their core, networks approximate a function that maps inputs to outputs. This work explores the question: can a single MLP approximate several different functions at once, without forgetting previously learned ones?
Each task is defined by a nonlinear function and distinguished using a task code. The naive approach would be to train the network on Task 1 (T1), then continue training on Task 2 (T2), and so forth. However, this typically leads to one of two outcomes:
- The weights drift from T1 to T2, causing the network to forget T1 (catastrophic forgetting).
- The weights compromise between T1 and T2, performing poorly on both.
The experiments show that while task-ID conditioning enables the network to fit all tasks under joint training, sequential training introduces interference and forgetting—highlighting the stability–plasticity dilemma.
Problem Setup
Five noiseless scalar regression tasks are defined on x ∈ [0.01, 2.02]:
- Task A: y = 10 - 5x
- Task B: y = eˣ
- Task C: y = ln(20x)
- Task D: y = x³
- Task E: y = 10sin(x)
The network must not only learn each function accurately, but also switch between tasks depending on the task code.
Methods
- Backbone: Fully connected MLP with four hidden layers (32, 64, 128, 32 units) and ReLU activations.
- Task conditioning: Scalar code (c \in {0,1,2,3,4}) concatenated to input (x). Ablations include one-hot encodings and learned embeddings.
- Normalization: Per-task z-scoring of targets (reversed for reporting) to balance scales across tasks.
- Optimization: Adam optimizer (learning rate = 2e-3), batch size 64, trained for 500 epochs.
Example Input Structure
For Task A, the input vector looks like:
| task_id | x |
|---|---|
| 0 | 0.01 |
| 0 | 0.02 |
| … | … |
Similarly, Task B uses task_id = 1, Task C = 2, and so on.
Results
The network successfully fits all five tasks when trained jointly, achieving low error across each function. However, when trained sequentially, clear interference emerges: performance on earlier tasks deteriorates after training on later ones.
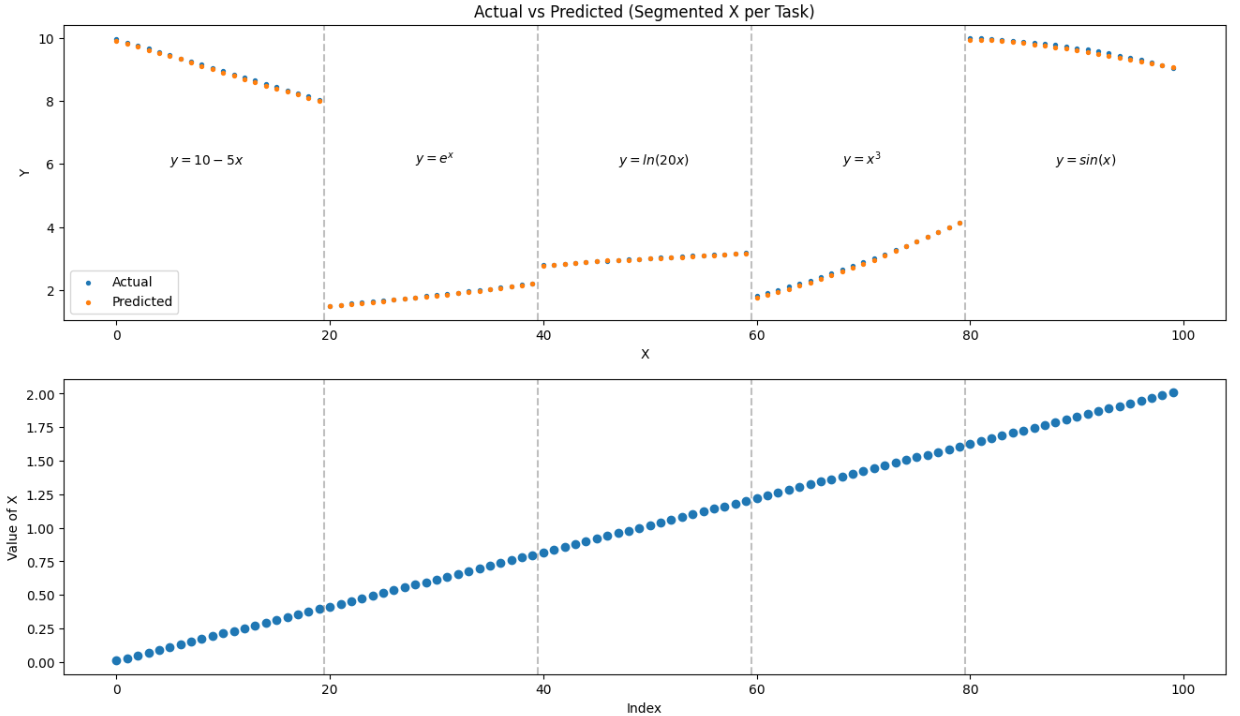
Plots of predictions vs. ground truth for each task show that the model approximates each function well when all tasks are trained together.
Discussion
The results illustrate that task-ID conditioning is sufficient to enable joint training of multiple tasks but fails under sequential training due to catastrophic forgetting. Replay buffers and regularization methods such as EWC can address this, but the simplicity of task-ID conditioning makes it an important baseline for future comparisons.
Limitations
- Synthetic, noiseless tasks only.
- Known task identifiers provided at train and test time.
- Experiments conducted on a single small MLP architecture.
- Replay methods not fully explored in this baseline.
Conclusion
Task-ID conditioning offers a clear and reproducible baseline for multi-task and continual learning research. While effective for joint training, sequential learning reveals strong forgetting effects. This highlights the stability–plasticity dilemma and sets the stage for evaluating more advanced continual learning strategies.